

Motivation
The rise of deep learning, particularly large language models, has gained significant attention in NLP, but lexical-semantic resources (LSRs) remain crucial for tasks like machine translation and word sense disambiguation. However, many LSRs, such as wordnets, are heavily biased toward English due to reliance on the Princeton WordNet for translations. This bias results in incomplete or inaccurate resources for non-English languages, underrepresenting culture-specific concepts without direct English equivalents. Consequently, NLP systems face limitations in fully capturing linguistic diversity and the richness of human language.
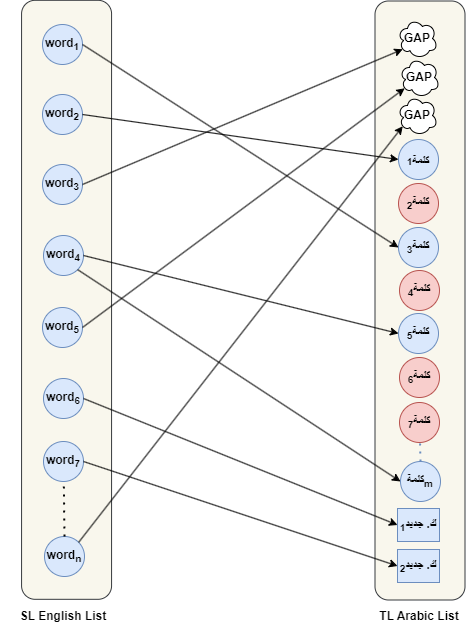
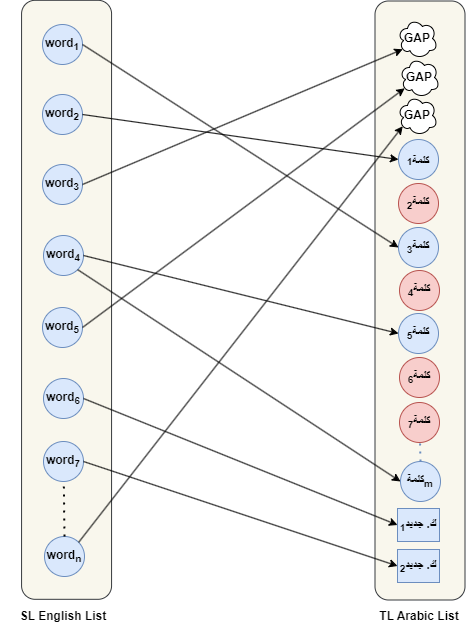
Lexical untranslatability, or cross-lingual lexical gaps, poses a significant challenge in NLP as some words lack direct equivalents across languages. For example, the Arabic word خالة (“mother’s sister”) has no English counterpart, while “sibling” has no precise equivalent in Arabic or other languages like Italian. These gaps affect machine translation and lexical resource quality, as seen in Google Translate’s flawed Arabic أنجب ابن عمه توأما rendering of “his cousin gave birth to a twin“, where it incorrectly implies a male giving birth due to the lack of an Arabic equivalent for “cousin”. The issue is more pronounced in low-resource languages, which are often underrepresented in multilingual lexical resources, further deepening linguistic disparities.
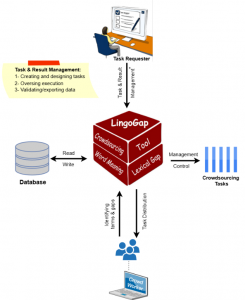
Figure 1
This project introduces a systematic approach for creating diversity-aware datasets through a novel crowdsourcing method—a bottom-up approach that engages native speakers from the general public. Crowd workers compare lexemes between two languages, focusing on domains rich in lexical diversity, such as kinship and food. The LingoGap crowdsourcing website facilitates these comparisons via microtasks that identify equivalent terms, language-specific terms, and lexical gaps across languages.
This methodology enables bidirectional exploration of lexical diversity between any two languages—from the source language (SL) to the target language (TL) and vice versa. Unlike traditional methods, it does not rely on English as an intermediate (pivot) language, thereby avoiding biases that can distort linguistic diversity. By capturing lexical gaps and equivalent terms across languages, including low-resource ones, this scalable method provides a viable alternative to conventional approaches. It generates high-quality, diversity-rich data and supports application across diverse language pairs, contingent on the availability of bilingual native speakers.
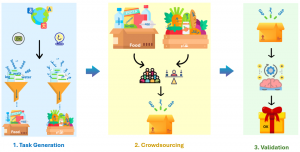
Figure 2
The initial inputs to our crowdsourcing methodology are an ordered source–target language pair and a specified semantic field. An overview of the crowdsourcing method is depicted in Figure 2. It includes three main steps:
- Task generation: A semi-automated process that generates two lists of lexical entries, one for each language, where each entry is a tuple (word, gloss), i.e., a term and its definition.
- Crowdsourcing: This step utilizes the LingoGap crowdsourcing website to compare lexical entries from the SL with corresponding TL entries. Native speakers assess these entries to determine translation equivalence or identify lexical gaps. LingoGap involves two primary roles: the task requester and the crowd worker. The task requester is responsible for the following critical functions: (1) constructing input datasets for both the SL and TL within the SF, (2) designing and creating crowdsourcing tasks, (3) overseeing task execution to ensure the quality of contributions, and (4) validating and exporting the finalized crowdsourced data. Additionally, the crowd worker’s role involves contributing to these tasks by identifying equivalent terms and lexical gaps in the TL.
- Validation: Lexical entries and gaps are evaluated automatically, followed by expert-based verification.
LingoGap Tool
Researchers can access the LingoGap website using the following links:
- Task Creation: Researchers (requesters) can create crowdsourcing tasks using this link: http://lingogap.disi.unitn.it/admin.jsp.
- Task Participation: Crowdworkers can complete crowdsourcing tasks via this link: http://lingogap.disi.unitn.it/.
How it works?
Step-by-step guidelines for using LingoGap are provided in this document, accessible via the following link: https://github.com/HadiPTUK/lingogap_instruction
Note: For assistance with importing source and target lists, uploading guidelines, or exporting the resulting data, please contact Hadi Khalilia, the project manager, via email at: hadi.khalilia@unitn.it.

Hadi Mahmoud Yousef Khalilia
Ph.D Student
University of Trento

Jahna Otterbacher
Associate Professor
Open University of Cyprus

Gabor Bella
Associate Professor
IMT Atlantique



