

Motivation
The rise of deep learning, particularly large language models, has gained significant attention in NLP, but lexical-semantic resources (LSRs) remain crucial for tasks like machine translation and word sense disambiguation. However, many LSRs, such as wordnets, are heavily biased toward English due to reliance on the Princeton WordNet for translations. This bias results in incomplete or inaccurate resources for non-English languages, underrepresenting culture-specific concepts without direct English equivalents. Consequently, NLP systems face limitations in fully capturing linguistic diversity and the richness of human language.
Lexical untranslatability, or cross-lingual lexical gaps, represents a significant challenge in NLP, as certain words lack direct equivalents in other languages. For instance, Google Translate has erroneously rendered the phrase “do not give cider to your child” into Arabic as لا تعطي عصير التفاح لطفلك, which translates back to “do not give apple juice to your child”. This mistranslation arises from the absence of a precise term for “cider” in Arabic, exposing a lexical gap. Similarly, the Arabic term الاحمران, meaning “bread and meat”, has been mistranslated into English as “red wine”, illustrating another instance of untranslatability caused by the lack of a corresponding term in English. This issue is especially pronounced in low-resource languages, which are often underrepresented in multilingual lexical databases, exacerbating linguistic inequities.

This project introduces a systematic approach for creating diversity-aware datasets through an expert-driven method—a top-down method that draws on the expertise of language specialists. The expert-driven method, widely used for creating small-scale datasets of lexical gaps in domains such as kinship and color, is extended in this study to cover a wider range of languages, enabling the generation of large-scale, diversity-aware datasets. This approach employs two human translators working from a source language (SL) to a target language (TL) to systematically identify lexical gaps, followed by validation from a target language specialist. Inputs for this method include an SL word list with definitions and a linguistic resource, such as a dictionary. An overview of the expert-driven method is depicted in Figure 2.
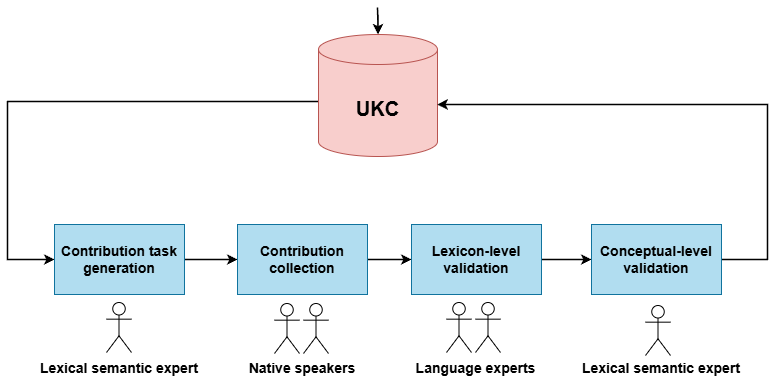
Figure 2: Methodology macro-steps and data sources
The process consists of four main steps:
- Contribution task generation: This step involves collecting SL data from the Universal Knowledge Core (UKC), a high-quality, diversity-aware multilingual lexicon that encompasses millions of words and meanings from over 2,300 languages. The data is then prepared in a spreadsheet file to be provided for translation into the TL. Each SL entry comprises a tuple (word, gloss), representing a term and its definition. Additionally, the data is formalized based on the UKC concept hierarchy.
- Contribution collection: The actual contribution effort is carried out by a native speaker in the TL language. For each SL word in the spreadsheet, the translator determines whether it has an equivalent meaning in the TL or constitutes a lexical gap.
- Lexicon-level validation: Provided words and gaps are evaluated and corrected by a language expert.
- Concept-level validation: New concepts and unclear contributions (i.e., words on the borderline) are verified by a lexico-semantic expert.
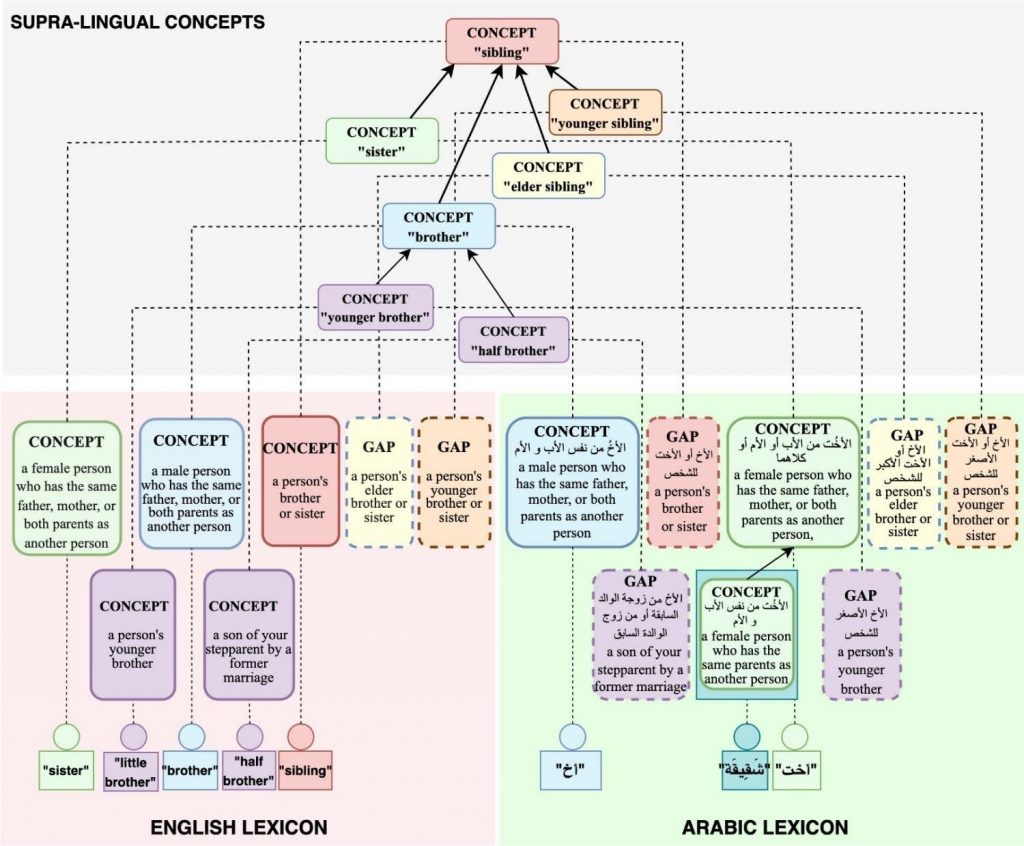
Figure 3: Structural elements in the UKC lexical database
This study led to the collection of 180 words, 1,108 lexical gaps, and 16 new concepts identified in the Arabic dialects. Detailed statistics on the collected words and gaps are presented in the following table. The new kinship concepts were integrated into the UKC by restructuring the supra-lingual concept layer within the domain hierarchy. For instance, the sibling hierarchy was expanded to include five new concepts related to brotherhood and five related to sisterhood. In the Arabic-Egyptian lexicon, as depicted in Figure 4, terms such as أخ في الرضاعة “breastfeeding brother” were added under a newly established concept for a brother. Additionally, أخ لأب “paternal brother” and أخ لأم “maternal brother” were linked to the half-brother concept. The newly introduced concepts and lexicalizations are represented as white nodes connected by blue lines.
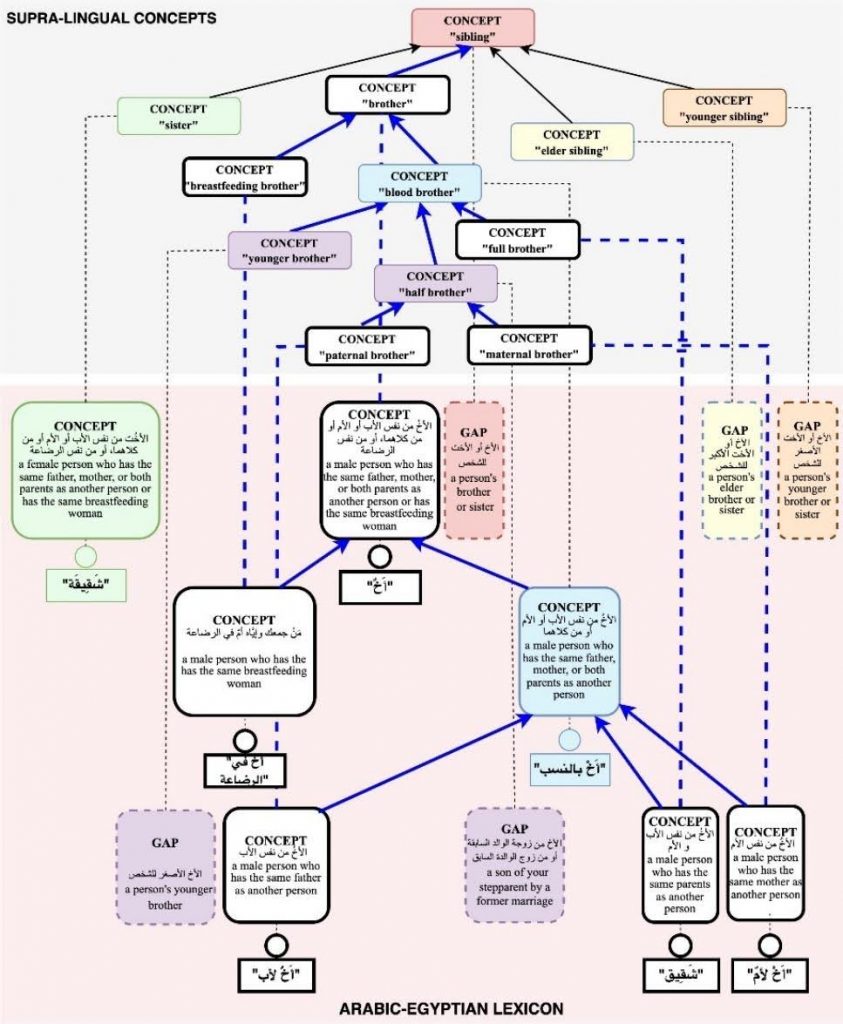
Figure 4: Structural elements in the UKC database after merging new concepts.
The resulting lexical units and gaps were incorporated into the UKC lexicons and made accessible through the UKC website, which provides system users with online browsing, source materials, and data visualization tools. This data was also integrated into the Arabic UKC, an ongoing project focused on developing a UKC instance for Arabic dialects. Figure 5 illustrates the concept exploration functionality with an example of the term أبله “elder sister”.
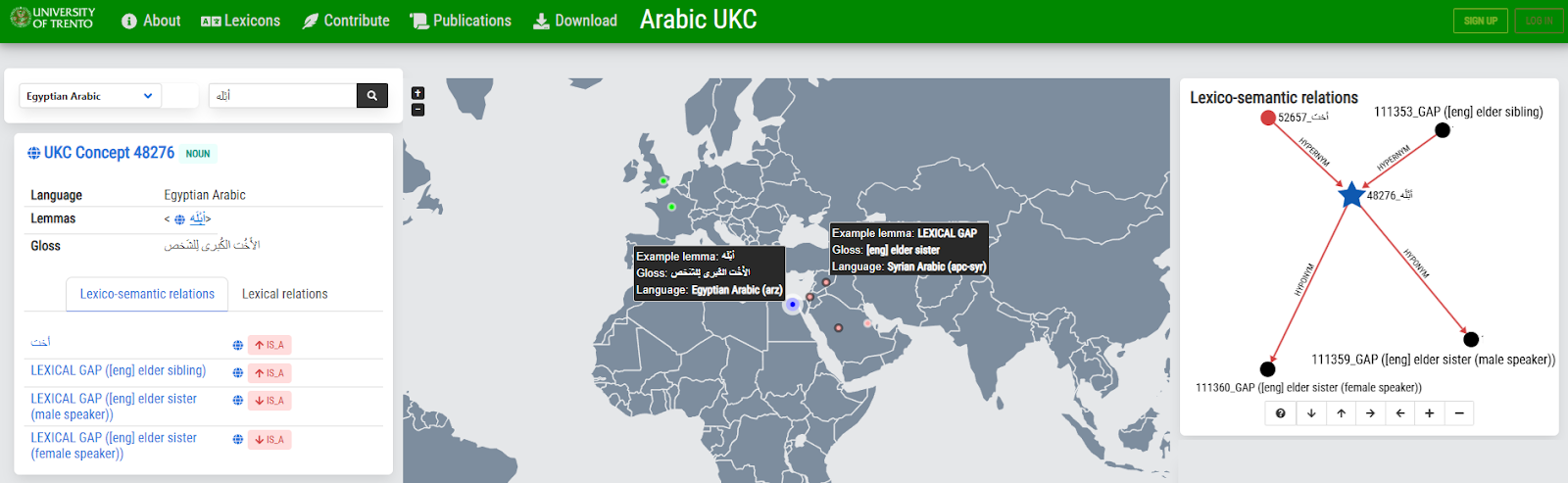
Figure 5: Homepage of the Arabic UKC ongoing project.
Figure 6 shows the overlaps between pairs of Arabic dialects over the kinship domain.
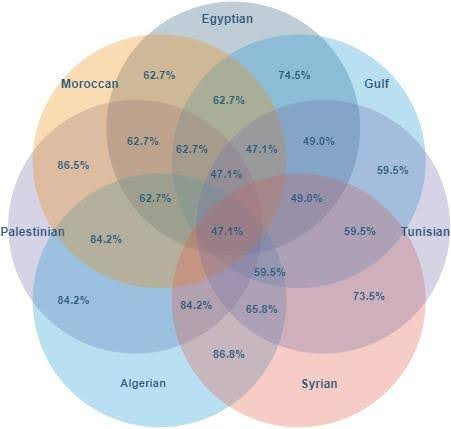
Figure 6: The overlap (percentage of shared lexicalizations) for Arabic dialects.
Further details about the collected data are provided in this link: (https://github.com/HadiPTUK/kinship_dialect).
Related Experiments
Indonesia, the world’s fourth most populous country, is home to over 700 living languages, with Bahasa Indonesia serving as the national language. This study examines the linguistic diversity in kinship terms across three Indonesian languages: Standard Indonesian, Banjarese, and Javanese. The findings reveal unique lexical gaps among these languages. For example, Javanese has the term ponakan jaler, meaning “nephew”, which is absent in Banjarese, while Banjarese includes gulu, meaning “a parent’s second eldest sibling”, a term not found in Javanese.
Using the expert-driven methodology, this study utilized the UKC lexicon to formalize 184 kinship concepts in the input dataset, and new concepts explored in three Indonesian languages. Native speakers—one per language—were recruited from their respective communities to identify relevant terms and lexical gaps. In Banjarese, resources such as the Kamus Bahasa Banjar Dialek Hulu-Indonesia and Google searches were employed to validate terms, particularly within the uncle/aunt subdomain. For instance, the Banjarese term gulu, meaning “a parent’s second eldest sibling”, was identified and verified through this process, marking its first documentation (a new concept) in the UKC.
The overall contribution effort resulted in the identification of 41 words and 517 lexical gaps across Indonesian, Javanese, and Banjarese. Furthermore, three previously unattested word meanings were identified and formalized as new concepts in this study. The table below provides a summary of the diversity items collected and identified in the Indonesian languages.
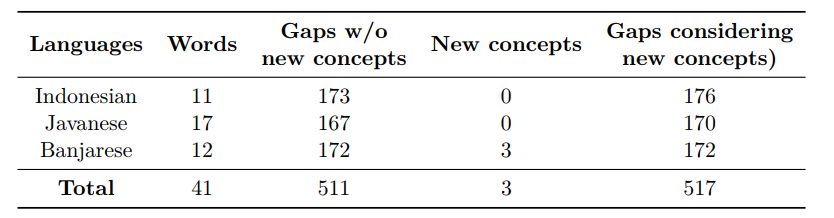
The new kinship concepts were integrated into the UKC by restructuring the supra-lingual concept layer within the domain hierarchy. Additionally, the resulting lexical units and gaps were incorporated into the UKC lexicons and made accessible through the UKC website, which provides system users with online browsing, source materials, and data visualization tools. This data was also integrated into the Indonesian UKC, an ongoing project focused on developing a UKC instance for Indonesian languages. Figure 7 illustrates the concept exploration functionality with an example of the Indonesian term kaka” meaning “elder sibling”.
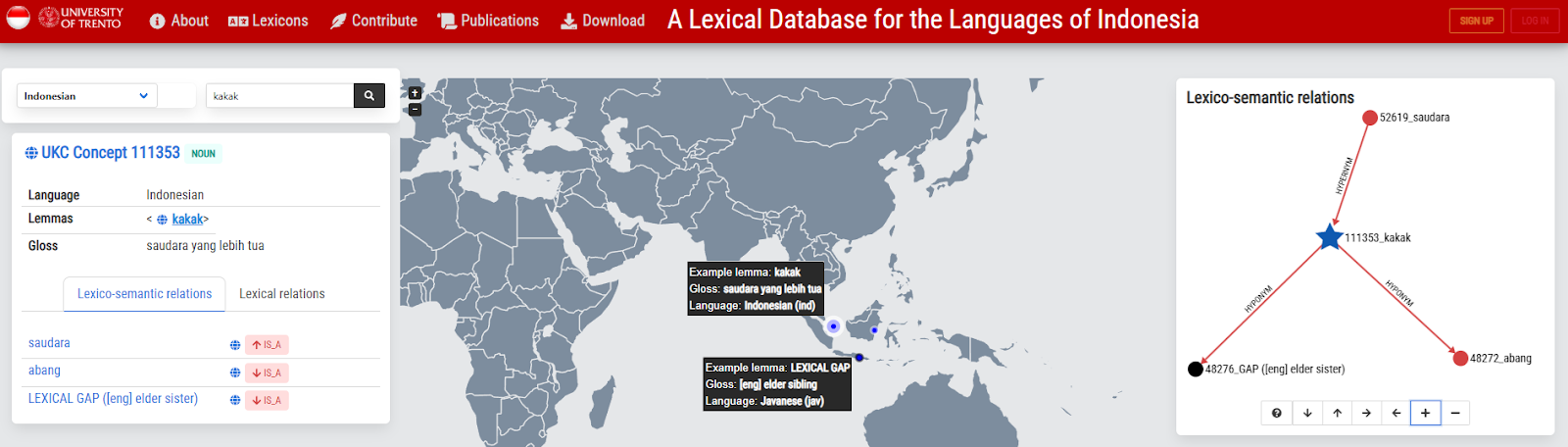
Figure 7: Homepage of the Indonesian UKC ongoing project.
Figure 8 shows the overlaps between pairs of Indonesian languages over the kinship domain.
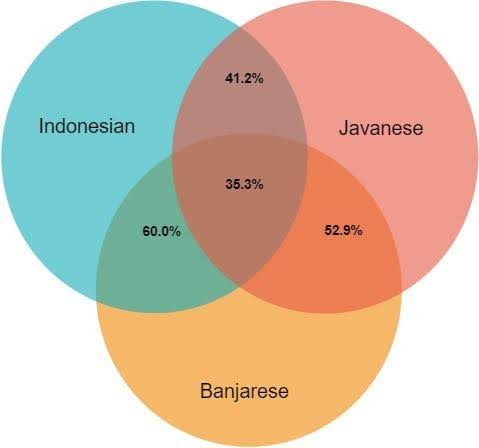
Figure 8: The overlap (percentage of shared lexicalizations) for Indonesian languages.
Further details about the collected data are provided in this link: (https://github.com/HadiPTUK/kinship_dialect).
Related Experiments
Our efforts in this experiment were part of the construction of the KinDiv lexicon project. This lexicon encompasses 1,911 words and identifies 37,370 gaps within the domain of kinship across 699 languages. A hybrid approach was employed in its construction, relying on three sources of evidence for lexicalization: Murdock’s lexicalization patterns, Wiktionary entries, and direct input from native speakers. The latter source represents our primary contribution to this study.
Using the expert-driven methodology, we utilized the UKC lexicon to enrich ten languages: Arabic, English, French, Hindi, Hungarian, Italian, Kannada, Malayalam, Mongolian, and Spanish. The UKC formalizes 184 kinship concepts in the input dataset, along with additional concepts explored in these languages. Native speakers—two per language (at least one of whom is a university instructor or a PhD student specializing in linguistics)—were recruited from their respective communities to provide lexicalization and gap information for all kinship concepts. This information served both as a basis for evaluating our approach and as a gold-standard reference for terms and gaps in languages where Murdock’s dataset or Wiktionary provided incorrect or incomplete data.
Our contribution to the development of the KinDiv lexicon includes 396 words and 1,503 lexical gaps, provided by native speakers of the ten languages. The table below provides a summary of the diversity items collected and identified in these languages.
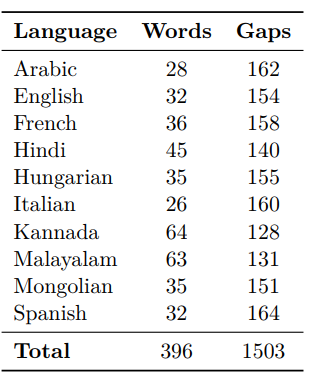
Moreover, 107 new words and collocations were collected. Notably, many missing terms were expressed through restricted collocations in Spanish, Mongolian, and Hungarian. For example, Mongolian speakers contributed 23 new entries, including restricted collocations such as ач хүү “son’s son” and нагац ах “maternal uncle”. Similarly, Spanish examples include hermano menor “younger brother” and tío materno “maternal uncle”, while Hungarian contributions featured fiúunoka “grandson” and nagytestvér “elder sibling”. Additionally, French contributors identified certain colloquial terms and morphological alternations, such as tata “aunt”, papi “grandfather”, and aîné “elder brother”.
For further details on the gathered contributions, refer to the dataset uploaded and integrated with the KinDiv resource (accessible by this link: (http://ukc.disi.unitn.it/index.php/kinship/), which is also available for direct download (accessible by this link: https://github.com/kbatsuren/KinDiv)
Related Experiments
The basic-level category, such as common everyday concepts, is a central notion in cognitive psychology, referring to the level of categorization that achieves an optimal balance between informativeness and cognitive efficiency. Basic-level categories, such as “chair” (as opposed to the superordinate “furniture” or the subordinate “rocking chair”), are the most cognitively salient, frequently used, and often the first categories learned by children. They encapsulate a rich set of shared attributes while remaining broad enough to encompass diverse examples. Research indicates that objects at the basic level are recognized, named, and remembered more quickly than those at superordinate or subordinate levels. Consequently, basic-level categories play a fundamental role in structuring human knowledge and facilitating efficient communication.
Using the expert-driven methodology, this study utilized the UKC lexicon to formalize 968 common concepts from the input dataset, along with new concepts explored in six languages: Arabic, Turkish, Persian, Indonesian, Javanese, and Banjarese. Native speakers—one per language—were recruited from their respective communities to identify equivalent terms and lexical gaps. Linguistic resources, such as the Almaany dictionary and Wiktionary, were employed sequentially, with Google Search used to ensure precise judgments in Arabic. In Indonesian and Banjarese, resources such as the Kamus Bahasa Banjar Dialek Hulu-Indonesia and Google Search were similarly employed.
The overall contribution effort led to the identification of 5,649 words and 159 lexical gaps across the six languages. For example, the concept “lair, den: the habitation of wild animals” represents a lexical gap in Arabic, where more specific terms exist, such as (جُحْر) (“a burrow, usually referring to the underground home of smaller animals like foxes, rabbits, or snakes”) and (عَرِين) (“a den of a lion or other large wild cats”). Another example is the concept “campfire: a small outdoor fire for warmth or cooking (as at a camp)”, which constitutes a lexical gap in both Turkish and Persian. The table below summarizes the diverse items collected and identified across these languages.”
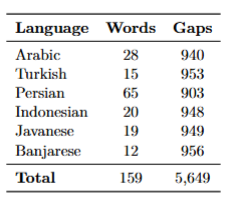
Further details about the collected data are provided in this link: https://github.com/HadiPTUK/generated_datasets
Related Experiments
High-quality WordNets are essential for achieving accurate results in NLP applications that depend on such resources. However, the WordNets of many languages face significant challenges regarding correctness and completeness in their lexical and semantic representations. These challenges include incorrect lemmas, missing glosses and example sentences, and an often inadequate, Western-centric portrayal of linguistic semantics. Previous efforts have primarily focused on expanding lexical coverage while overlooking other critical qualitative aspects. In this study, we focus on the Arabic language and present a substantial revision of the Arabic WordNet, addressing multiple dimensions of lexico-semantic resource quality. Through the expert-driven methodology, we achieved significant improvements in correctness, completeness, and linguistic diversity, tackling key challenges in the Arabic WordNet.
Our efforts led to the enhancement of over 58% of synsets by supplementing missing components and correcting errors. Additionally, we introduced innovative features such as phrasets—combinations of words used to express synset meanings when no direct equivalent lemmas exist—and lexical gaps, enabling the explicit representation of untranslatable concepts. These additions enrich the resource’s ability to capture linguistic diversity. This work culminated in the release of AWN V3, a significantly more accurate, complete, and accessible version of the Arabic WordNet, optimized for both human and NLP applications.
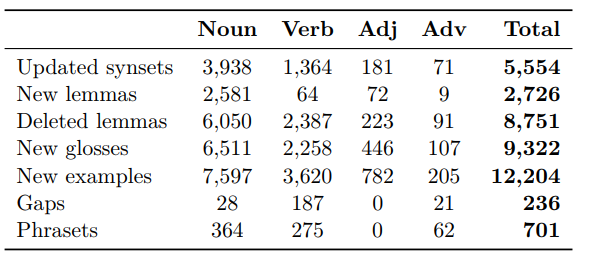
The overall effort to collect contributions resulted in updating 5,554 synsets from AWN V1. Specifically, we added 2,726 new lemmas, 9,322 new glosses, and 12,204 new example sentences. Additionally, we identified 236 lexical gaps and introduced 701 phrasets. Furthermore, 8,751 incorrect lemmas were removed. A detailed breakdown of these contributions is presented in the table below, and additional information about the dataset can be accessed through the following link: https://github.com/HadiPTUK/AWN3.0
Related Experiments

Hadi Mahmoud Yousef Khalilia
Ph.D Student
University of Trento

Gabor Bella
Associate Professor
IMT Atlantique

Abed Alhakim Freihat
Assistant Professor
University of Trento



